Как создать robots.txt, настроить для SEO и загрузить на сайт
Robots.txt – это документ c именем robots и расширением .txt, в котором содержаться директивы (указания) для роботов (веб-краулеров) поисковых систем (ПС), запрещающие или разрешающие индексирование (добавление в базу/индекс ПС) конкретных страниц сайта. Этот файл закрывает доступ веб-краулерам к определенному содержимому сайта.
Использование robots.txt было принято на World Wide Web Consortium, который состоялся 30.01.1994 г. Именно с того времени он на добровольной основе используется большей частью ПС, хотя данный стандарт не обязателен для исполнения.
Использование robots.txt в SEO продвижении
В ходе технического аудита SEO-специалисты поверяют размещение файла robots.txt на сайте и анализируют его заполнение, т.к. случайным образом могут быть закрыты значимые для продвижения разделы сайта/весь сайт или наоборот, для индексации доступны мусорные страницы.
В процессе дальнейшей работы над оптимизацией ресурса файл robots.txt настраивается SEO-специалистами исходя из потребностей того или иного проекта и чаще всего нужен для:
- Закрытия от добавления в базу ПС служебных разделов ресурса, которые не содержат важной информации для посетителей;
- Закрытия от добавления в базу ПС страниц, создающих дубли (страницы поиска товаров на сайте, фильтрация, страницы с параметрами);
- Разделения правил добавления в базу страниц для веб-краулеров Яндекс, Google и других ПС;
- Разрешения добавления в базу определенных страниц (например, если весь раздел закрыт от индексации, но несколько конкретных страниц должны попадать в индекс)
Проверка наличия файла robots.txt на сайте
Существование файла robots.txt можно проверить через браузер по ссылке https://yoursite.ru/robots.txt, где https://yoursite.ru/ адрес анализируемого сайта, если по запрошенному адресу появились директивы, то файл на сайте размещен, если возникла 404 ошибка, то необходимо создать и загрузить файл на сайт.
[caption id="attachment_1871" align="alignnone" width="279"]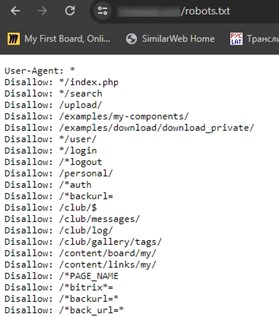 Пример проверки наличия файла robots.txt через браузер[/caption]
Пример проверки наличия файла robots.txt через браузер[/caption]
Сам документ находится/загружается строго в корневую папку сайта. В которую можно попасть через:
- FTP-клиент (TotalCommander, FileZilla и т.д.)
[caption id="attachment_1873" align="alignnone" width="404"]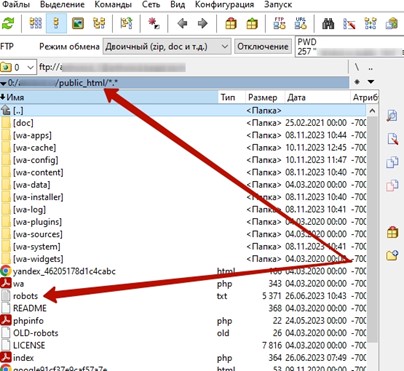 Пример проверки наличия-загрузки файла robots.txt с помощью FTP-клиент[/caption]
Пример проверки наличия-загрузки файла robots.txt с помощью FTP-клиент[/caption]
- административную панель CMS
[caption id="attachment_1875" align="alignnone" width="527"]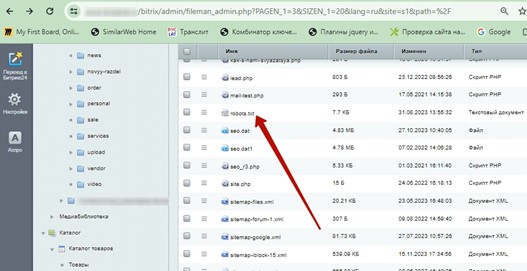 Пример проверки наличия - загрузки robots.txt через административную панель CMS[/caption]
Пример проверки наличия - загрузки robots.txt через административную панель CMS[/caption]
- через панель управления сервером
[caption id="attachment_1876" align="alignnone" width="457"]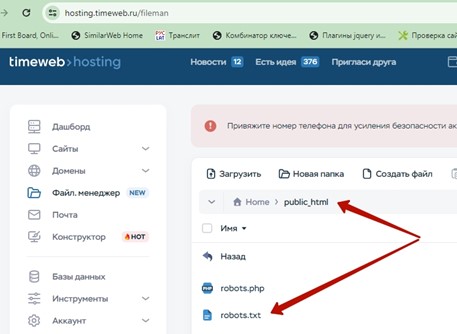 Пример проверки наличия-загрузки файла robots.txt через панель управления сервером[/caption]
Пример проверки наличия-загрузки файла robots.txt через панель управления сервером[/caption]
Создание файла robots.txt
Файл создается с помощью текстовых редакторов (Блокнот Windows, Sublime Text, Microsoft Word, Note Pad++ и др.). Назвать файл следует строго “robots” в нижнем регистре, при его сохранении необходимо выбрать расширение .txt с кодировкой UTF-8, которая должна включать коды символов ASCII. Допускается размер файла не более 500 КБ.
Заполнение файла robots.txt
В документе прописываются указания необходимые для конкретного ресурса, ниже приведены директивы (указания) в той последовательности, в которой они обычно прописываются и пояснения к ним.
Директива User-agent
С этой строчки начинается все содержимое файла robots.txt. Заполнение этого указания обязательно, т.к. оно определяет к какому поисковику будут применять правила, прописанные в документе ниже.
Текст после символа # веб-краулеры не учитывают, после него обычно пишут пояснения к указаниям. Перевод строки на новую отменяет действие символа. В рабочем варианте файла их можно не писать.
User-agent: * #для веб-краулеров всех ПС
User-agent: Yandex #для веб-краулера Яндекс
User-agent: GoogleBot #для веб-краулера Google
Не смотря на возможность задать указания для ботов сразу всех ПС, лучше прописывать отдельные группы для Yandex и Google, таким образом они лучше воспринимают указания.
User-agent: Yandex #веб-краулеру Яндекс
Disallow: /wp-admin #запретить индексировать страницы административной панели
Disallow: /oborudovanie/* #запрещено добавлять в базу страницы раздела оборудование
User-agent: GoogleBot - веб-краулеру Google
Disallow: /wp-admin #запрещено индексировать страницы панели администратора
Директива Disallow
Это указание запрещает добавление в базу ПС страниц и разделов. С ее помощью закрывают контент, который не должен попасть в базу (служебные страницы, страницы админ. панели, поиск, страницы пагинации, дубли и т.д.).
По умолчанию роботы индексируют все страницы и разделы сайта, если это не запрещено директивой Disallow.
Disallow: /wp-admin #запрещено индексировать страницы административной панели
Disallow: /*?* #запрещено индексировать страницы поиска по сайту
Disallow: /*?page #запрещено индексировать страницы пагинации
Disallow: /index.php #запрещено индексировать страницы с index.php
Disallow: *session_id= #запрещено индексировать страницы с идентификатором сессий
Disallow: /oborudovanie/* #запрещено индексировать страницы раздела оборудование
В синтаксисе директив запрещено использование кириллических символов, доменные имена на кириллице необходимо преобразовать в последовательность ASCII-символов с помощью Punycode-конвертера.
Disallow: /корзина #некорректно
Sitemap: твойсайт.рф/sitemap.xml #некорректно
Disallow: /xn--80andgrdo #корректно
Sitemap: https: //xn--80advbwtdg.xn--p1ai/sitemap.xml #корректно
С помощью символов * и $ указание Disallow можно уточнить
Disallow: /oborudovanie/* #разрешает любую последовательность символов
т.е. для краулеров закрыты все страницы, относящиеся к разделу /oborudovanie/, например, страницы вида /oborudovanie/stanki/ или /oborudovanie/dlya_proizvodstv/ и т.д.
Disallow: /oborudovanie/$ #указывает на конкретный адрес
т.е. для индексации закрыта только страница раздела /oborudovanie/, все остальные страницы этого раздела доступны для индексации.
Для написания указаний важно соблюдение регистра символов
Disallow: /Oborudovanie/* #директива не применима к папке /oborudovanie/
Disallow: /oborudovanie/* #директива применима к папке /oborudovanie/
Чтобы полностью закрыть сайт от попадания в базы всех ПС, применяется следующая форма записи
User-agent: * #веб-краулерам всех ПС
Disallow: / #запрещено добавлять в индекс все страницы сайта
Директива Allow
Это указание разрешает добавление в индекс страниц, файлов и разделов. В ней указываются те разделы или документы, которые должны быть доступны для роботов ПС.
Если директивы Disallow и Allow противоречат друг другу, приоритетной для веб-краулера будет директива Allow.
Disallow: /oborudovanie/* #закрыты от индексации все страницы раздела
Allow: /oborudovanie/stanki/ #открыта для индексации конкретная страница раздела
Директива Clean-Param
Это указание запрещает веб-краулерам добавлять в базу ПС страницы с динамическими параметрами. На некоторых сайтах возникает проблема попадания в индекс страниц с динамическими параметрами (страницы с данными источников сессий, данными идентификаторов посетителей и т.д.), т.о. создаются множественные дубли основных страниц.
Из-за большого количества страниц с параметрами краулеры медленно обходят сайт и нужные изменения дольше попадают в результаты поисковой выдачи. Для эффективного продвижения сайта важно своевременно обновлять список Clean-Param. Страницы с параметрами можно обнаружить в панели Яндекс.Вебмастер, они часто являются причиной появления дублей.
Clean-Param: page&eligibilityByStores&06575&01746&10837 #веб-краулеры не будут индексировать страницы с указанными параметрами
Подробно о том, как находить параметры в URL и правильно составить указание краулеру смотрите в видеоинструкции Яндекс.Вебмастер
Директива Sitemap
Это указание показывает веб-краулерам путь к XML- карте сайта, которая помогает им быстрее добавить ресурс в базу ПС, в ней они находят информацию о последних изменениях и приоритетах добавления страниц.
Sitemap: https://yoursite.ru/sitemap.xml
Директива Crawl-delay
Это указание позволяет регулировать частоту обращений веб-краулера к сайту в определенном временном интервале, чтобы сократить нагрузку на сервер.
22.02.2018 года веб-краулер ПС Яндекс перестал воспринимать директиву Crawl-delay, вместо неё появился новый инструмент в панели Яндекс.Вебмастера «Скорость обхода».
Директива Host
Это указание сообщает веб-краулеру какое зеркало сайта считать основным - оно предназначалась только для Яндекса.
С 2018 года больше не используется, вместо неё появился новый инструмент в панели Яндекс.Вебмастера «Переезд сайта».
В конечном варианте должен получиться файл с набором указаний для веб-краулеров
[caption id="attachment_1877" align="alignnone" width="624"]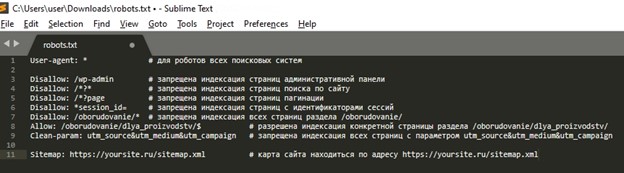 Пример заполнения файла robots.txt с помощью SublimeText с расшифровкой указаний[/caption]
Пример заполнения файла robots.txt с помощью SublimeText с расшифровкой указаний[/caption]
Загрузка файла robots.txt на сайт
Итоговый файл необходимо загрузить на сайт в корневую папку. Подробно варианты загрузки файла были рассмотрены в пункте «Проверка наличия файла robots.txt на сайте»
Способы быстрого создания robots.txt
Автосоздание - самый быстрый способ создания файла robots.txt, в том случае, если оно возможно в используемой CMS или с помощью дополнительно установленных плагинов для генерации robots.txt.
Позаимствовать шаблон на стороннем сайте с той же CMS - к названию домена «донора» добавляем «robots.txt», пример - https://yoursite.ru/robots.txt и получаем содержимое файла. Но т.к. у каждого сайта свой набор правил, следует внимательно изучить заимствованный файл и оставить только те указания, которые являются стандартными, все остальные необходимо добавлять самостоятельно.
Найти готовый шаблон в сети – для большинства CMS (WordPress, Битрикс и т.д.) в сети можно найти готовые примеры robots.txt, в которых собраны стандартные указания для той или иной CMS.
С помощью онлайн генератора – в сети много онлайн сервисов для создания файла robots.txt, такой вариант удобен, но также как и другие требует проверки и внесения дополнительных правок.
Т.к. у каждого сайта свой набор указаний, SEO-специалисты внимательно проверяют файл robots.txt, взятый за основу.
Проверка корректного составления файла robots.txt
После загрузки файла на сайт необходимо проверить его доступность через браузер по адресу https://yoursite.ru/robots.txt, где https://yoursite.ru/ адрес анализируемого сайта.
Если файл недоступен необходимо сделать несколько проверок: в ту ли папку был загружен файл, нет ли ошибок в названии файла или формате, а также не превышает ли размер файла допустимый.
Если файл доступен его необходимо проверить на наличие ошибок в панелях вебмастеров Яндекс и Google.
В панели Яндекс.Вебмастер инструмент проверки robots.txt называется «Анализ robots.txt»
[caption id="attachment_1880" align="alignnone" width="374"]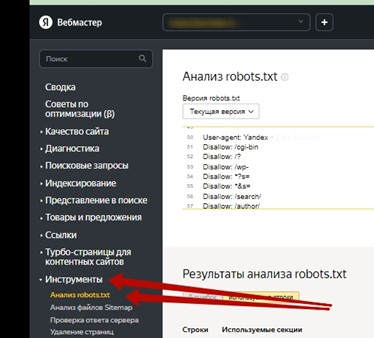 Пример поиска ошибок в robots.txt через панель Яндекс.Вебмастер[/caption]
Пример поиска ошибок в robots.txt через панель Яндекс.Вебмастер[/caption]
В этом же инструменте можно проверить запреты для отдельных страниц
В панели Google Search Console инструмент проверки robots.txt находится в разделе «Настройки»
[caption id="attachment_1882" align="alignnone" width="624"]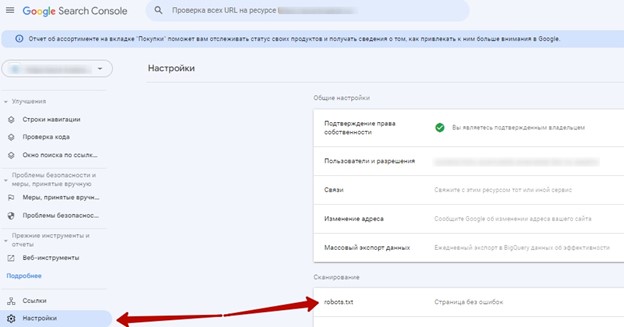 Пример поиска ошибок в robots.txt через панель Google Search Console[/caption]
Пример поиска ошибок в robots.txt через панель Google Search Console[/caption]
Пример поиска ошибок в robots.txt через панель Google Search Console
Внесение изменений в файл robots.txt
В ходе работ по SEO оптимизации сайта, часто требуется вносить дополнительные указания к тем, которые были внесены изначально. В этом случае файл скачивается из корневой папки сайта на локальный компьютер и в текстовом редакторе в него вносятся необходимые изменения. Затем файл с правками загружают обратно в корневую папку сайта вместо исходного варианта. В некоторых CMS есть возможность вносить правки сразу в административной панели.
Не допускается размещение на сайте более одного файла robots.txt
Заключение
Robots.txt является эффективным инструментом SEO-оптимизации, с его помощью настраивается добавление в базу ПС только нужных для поискового продвижения страниц, что способствует экономии краулингового бюджета, снижению нагрузки на сервер и своевременному применению важных изменений на страницах ресурса.