Мусорные страницы сайта: как найти и удалить из индекса
Интернет - это как огромная библиотека. Но что делать, если в этой библиотеке оказались книги, которые вам не нужны? В мире SEO ситуация аналогична: ваш сайт - это ваша книга, и важно, чтобы в поисковых системах хранились только те страницы, которые действительно важны для вас и ваших посетителей. В этой статье мы расскажем, как избавиться от "мусорных" страничек и почему это так важно.
Какие страницы являются мусорными
Перед тем как приступить к удалению лишних страничек, давайте разберемся, какие из них считаются "мусорными". Это те, которые не приносят ценности вашему сайту или даже могут нанести вред. Это могут быть страницы:
- Пустые или заполненные бессмысленным контентом страницы с низкой уникальностью;
- С дублирующимся контентом;
- С устаревшей или неактуальной информацией;
- Созданные для тестирования и забытые;
- Документы PDF, XLS, DOC;
- Версии для печати;
- Пагинации;
- Служебные;
- Формы или личные кабинеты пользователей;
- Малоценные с незначительным количеством контента;
- Дубликаты;
- Ошибки оформления или верстки;
- С кодом 404, 301 редиректом или отличным от 200 кодом ответа сервера;
- С отсутствием канонизации
Каким образом ненужные страницы попадают в индекс?
В перечень известных поисковым системам документов попадают и некачественные документы сайта. Это происходит по ряду причин, и понимание этих факторов важно для эффективного управления индексацией. Выделим основные проблемы:
Особенности CMS
CMS (Content Management System) – это инструмент, который облегчает создание, редактирование и управление контентом на веб-сайте. Но иногда из-за различных факторов CMS может привести к генерации плохих документов, описанных выше. Эффективное управление CMS поможет избежать создания мусорных страниц и поддерживать высокое качество вашего веб-сайта.
На сегодняшний день редкость встретить статичные веб-сайты, созданные в формате HTML-страниц. Чаще всего для разработки используются разнообразные системы управления контентом (CMS). У каждой CMS есть свои уникальные характеристики и недостатки.
Дублирование и сохраненные старые версии
Частая ошибка для старых сайтов, на которых периодически обновляют и редактируют контент или функционал. Такие старые ссылки могут оставаться в индексе. Вот одни из вариантов:
- Разные URL с одним и тем же контентом:
Это одна из наиболее распространенных причин дублирования. Одна и та же страница может быть доступна по нескольким URL, например, с и без "www" или с разными параметрами запроса. Поисковые роботы могут воспринимать эти URL как разные страницы, даже если контент идентичен.
Пример:
http://example.com/page
http://www.example.com/page
http://example.com/page?source=google
- Динамические параметры URL:
Если ваш сайт использует в URL динамические параметры (сортировка, фильтрация и др.), каждая комбинация параметров может создавать новый URL. Это приводит к тому, что один и тот же контент отображается на разных URL.
Пример:
http://example.com/category/page
http://example.com/category/page?sort=asc
http://example.com/category/page?filter=recent
- Псевдодублирование через HTTP и HTTPS:
Если сайт предоставляет контент через HTTP и HTTPS, поисковые системы могут воспринимать оба протокола как разные версии страницы, даже если контент идентичен.
Пример:
http://example.com/page
https://example.com/page
- Множественные версии одной страницы:
Это может произойти, если на сайте есть несколько версий одной страницы. Например, для разных языков или устройств (мобильных и десктопных).
Пример:
http://example.com/page
http://example.com/en/page
http://m.example.com/page
Незакрытые от индексации файлы
Файлы в форматах doc, xls, pdf и др. иногда могут быть включены в индекс поисковых систем как отдельные страницы сайта. Чтобы этого избежать, рекомендуется установить запрет на индексацию в обеих поисковых системах. К тому же такие страницы не привлекут посетителей на сайт, и взаимосвязь страниц будет нарушена.
Зачем находить такие документы?
Поисковые роботы регулярно сканируют страницы сайта, имеющиеся в их базе данных. Однако количество страниц, доступных для индексации в течение суток, ограничено краулинговым бюджетом. Эффективное использование этого бюджета становится проблемой, когда робот тратит его на проход по мусорным страницам, что замедляет доступ к качественным и важным материалам, и, следовательно, приводит к индексации меньшего объема контента.
Поскольку поиск может включать в себя даже низкокачественные страницы, их присутствие может серьезно повлиять на общий рейтинг сайта в поисковой выдаче. Кроме того, избыток мусорных страниц может вызвать применение фильтров и санкций, что ограничит видимость важных страниц в поиске и, следовательно, уменьшит трафик на сайт.
Как найти такие страницы?
Чтобы выявить подобные страницы, необходимо использовать аккаунты в Яндекс.Вебмастере и Google Search Console, где предоставляется подробная информация об индексации и других важных моментах.
Прежде всего, необходимо получить список страниц текущего индекса сайта в определенной поисковой системе. Это можно сделать следующим образом.
- Собрать проиндексированные страницы в Яндексе
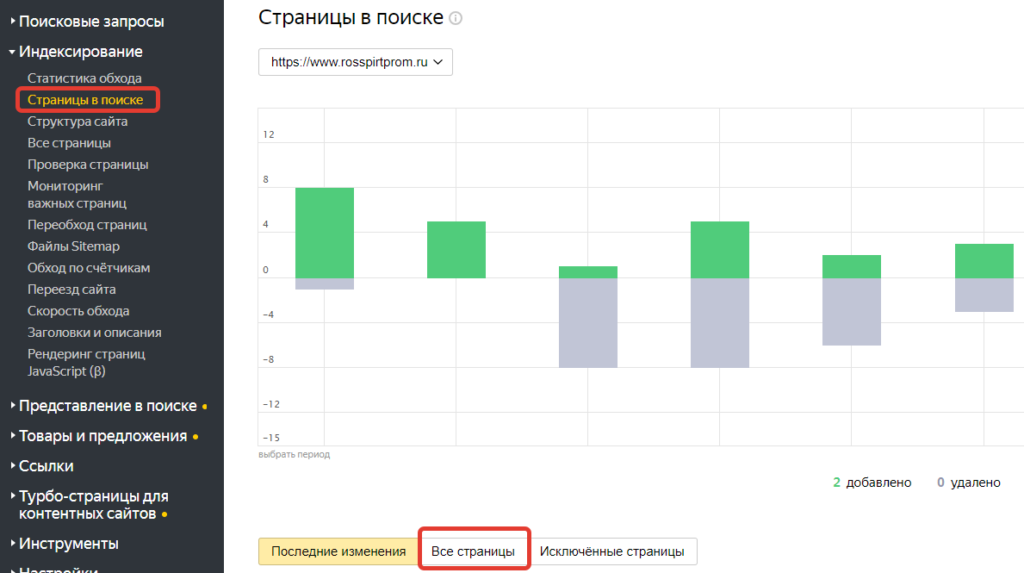
Для страниц, проиндексированных в поисковой системе Яндекс, перейдите в раздел "Страницы в поиске" в Яндекс.Вебмастере, просмотрите список этих страниц и скачайте выгрузку "Все страницы" в формате XLS или CSV.
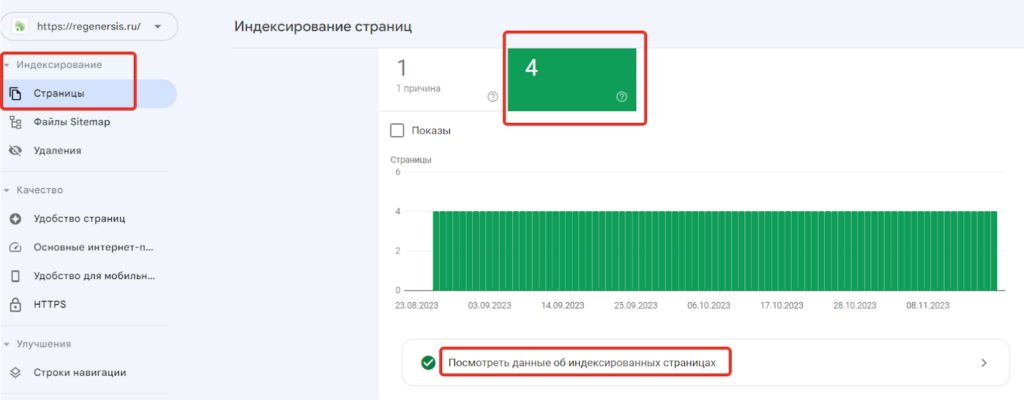
- Страницы, проиндексированные в Google, можно увидеть в Google Search Console, перейдя в раздел Индексирование - Страницы и выделив группу проиндексированных страниц (отображенных зеленым цветом).
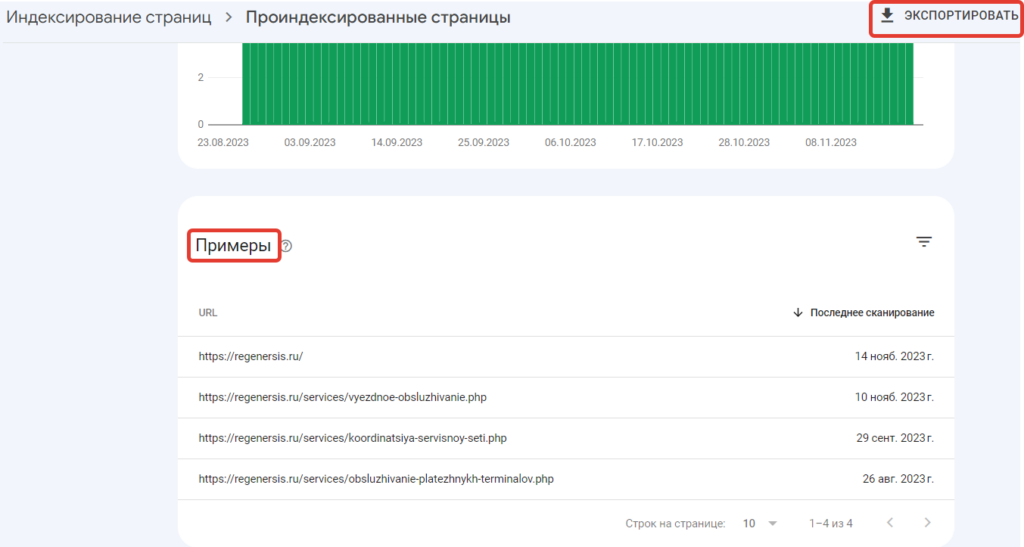
Ниже можно провалиться в раздел с перечнем всех этих страниц, где можно выгрузить данные в формате Google таблицы, CSV или скачать таблицу EXCEL.
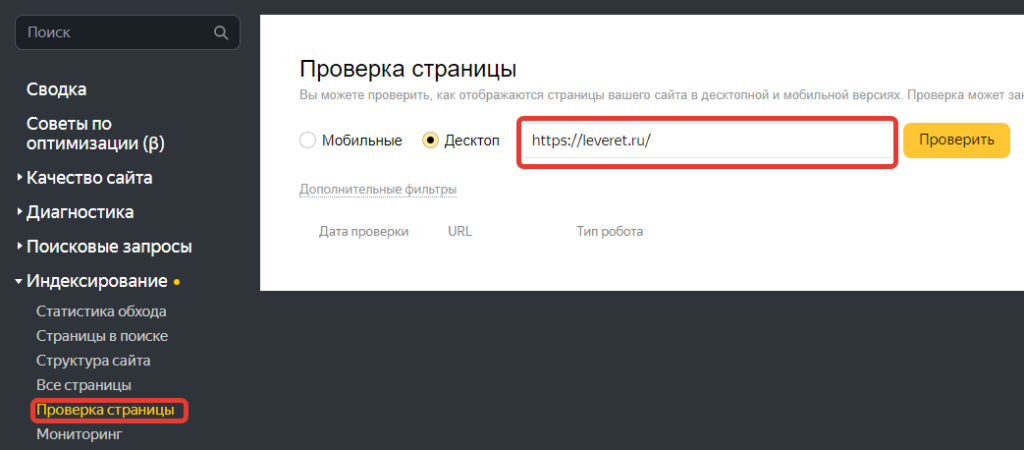
Посмотреть присутствие конкретной страницы в индексе любой поисковой системы можно, используя оператор поиска url:yoursite.ru/page1. Вбив запрос в таком формате, мы увидим в выдаче эту страницу.
Проверить конкретный url также можно и в Вебмастере при помощи инструмента “Проверить статус url”, введя ссылку и выбрав версию страницы (Мобильная или Десктоп).
- Проанализировать собранные списки страниц в индексе.
После сбора всех страниц, известных поисковым системам, необходимо сравнить эти 2 списка с перечнем страниц, доступных для индексации, полученным любым краулером (Screaming Frog SEO Spider, SiteAnalyzer и др.). Для того, чтобы выявить расхождения в списках, можно воспользоваться функциями Excel или сервисами типа https://bez-bubna.com/free/compare.php.
По результатам сравнения можно понять, какие страницы и почему находятся или отсутствуют в индексе, и предпринимать дальнейшие действия. Прежде всего, не стоит торопиться с выводами. Нужно как следует разобраться, что за страницы были исключены.
Как удалить их из индекса
- Директива Disallow в robots.txt
Самый простой способ исключить мусорные страницы из индекса - использовать файл robots.txt. С помощью директивы Disallow можно запретить поисковому роботу Яндекса или Google индексировать определенную страницу или целый раздел. Этот метод обычно применяется для исключения из индекса страниц, предназначенных для внутреннего использования.
— Отключить индексацию всем поисковым роботам:
User-agent: *
Disallow: /
— Запретить индексацию сайта для Яндекса:
User-agent: Yandex
Disallow: /
— Запретить индексацию всем роботам, за исключением одного, например, Яндекса:
User-agent: *
Disallow: /
User-agent: Yandex
Allow: /
— Запретить индексацию отдельной страницы или раздела:
User-agent: *
Disallow: /news/*
Однако следует учесть, что закрытие страницы не приведет к мгновенному её исключению из индекса. Этот процесс займет определенное время.
- Удаление ненужных страниц с сайта.
Если страница не активно используется, не привлекает трафик на сайт и не предполагается ее изменение, безопасно удалить ее. При доступе к странице с соответствующим URL поисковый робот обнаружит код ответа сервера 404, что со временем приведет к ее исключению из индекса. Однако не для всех сайтов реализация этого метода возможна.
- Атрибут Noindex в коде страницы.
Для того чтобы передать информацию поисковым системам о рекомендации не индексировать страницу, необходимо внести изменения в html-код страницы, добавив атрибут noindex в соответствующий элемент <head>.
<meta name="robots" content="noindex">
При обнаружении данной директивы, поисковые роботы, включая краулеры Яндекса и Google, исключат данную страницу из индекса, даже в случае наличия возможных ссылок, указывающих на неё.
- Установка 301 редиректа.
Установка 301 редиректа является первоочередной мерой при наличии дублирующихся страниц на сайте. Рекомендуется устанавливать 301 редирект с каждой мусорной страницы на соответствующую целевую. Если производится перенаправление с нескольких страниц на одну, поисковики могут рассматривать это как подозрительное действие, что может негативно сказаться на рейтинге страницы. Для того чтобы закрытые мусорные страницы скорее выпали из индекса поисковых систем, стоит воспользоваться инструментами в панелях вебмастеров Яндекса и google.
- Яндекс.Вебмастер.
Процедура выглядит следующим образом:
- Перейдите в раздел инструментов "Удаление страниц из поиска" в Вебмастере.
- Вставьте список URL мусорных страниц и нажмите кнопку "Удалить".
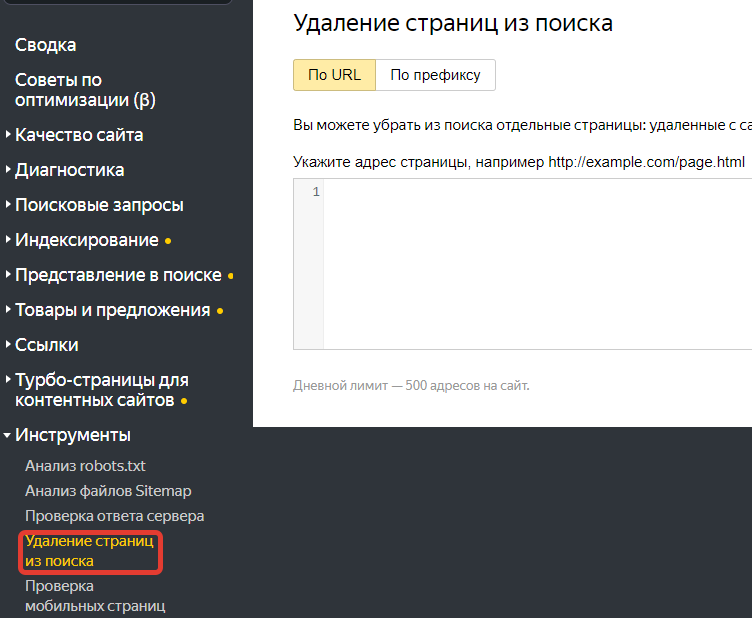
Важно! Для успешного удаления страницы необходимо, чтобы она возвращала код 404 или была закрыта от индексации с использованием robots.txt или другими методами.
- Google Search Console
Использование Google Search Console для удаления страниц из индекса Google также просто, как и в Яндексе. Достаточно перейти в раздел "Удаления" и создать запрос, указав URL.
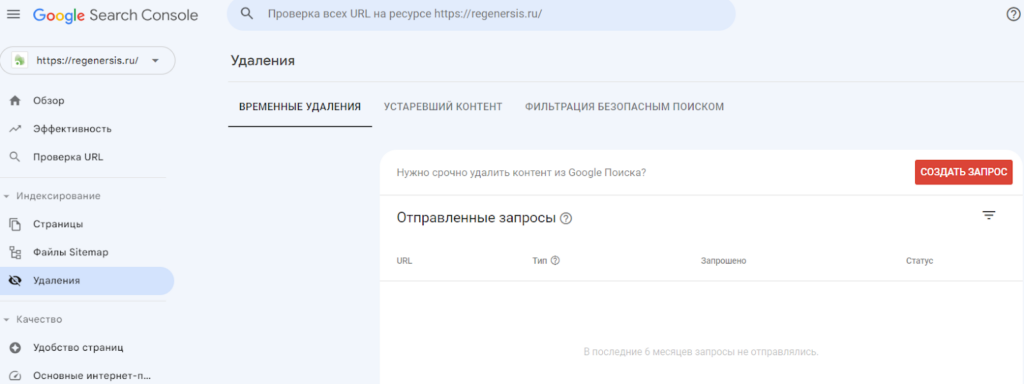
На скриншоте видно, что доступны два варианта удаления: конкретного URL и группы URL с общим префиксом. Такой метод удаления, конечно, может занять некоторое время.
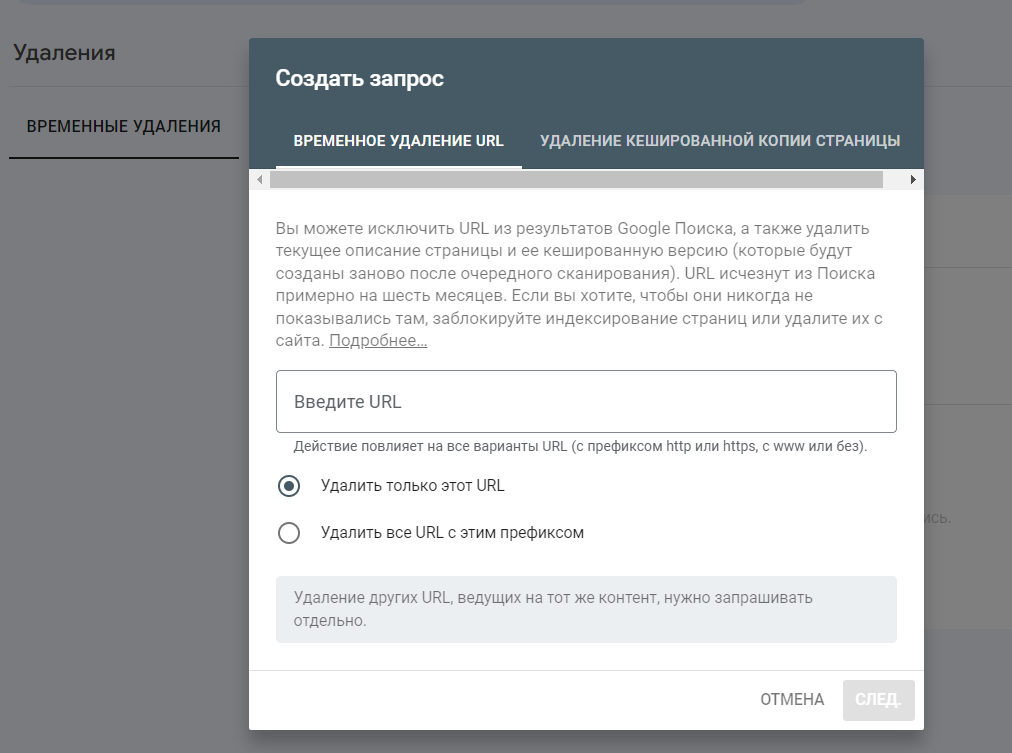
Замедленная скорость удаления страниц в Google представляет собой существенный недостаток. Решением данной проблемы может быть использование инструмента Google Indexing API. Этот инструмент предоставляет возможность напрямую информировать роботов Google о страницах, которые необходимо добавить или исключить из индекса. С помощью Google Indexing API вы можете отправлять до 200 страниц в день, разбивая их на части по 100 URL за раз. Этот метод существенно ускоряет процесс по сравнению с ручной отправкой запросов. Инструкции по настройке API представлены в данной статье https://pixelplus.ru/samostoyatelno/stati/indeksatsiya/indexing-api-v-google.html
Заключение
Мусорные страницы периодически появляются на любом сайте, мешая его продвижению и не принося никакой пользы пользователям и владельцам. Теперь у вас есть знания о том, какие страницы считаются мусорными и как с ними поступить. Следуя предложенным рекомендациям, вы сможете избежать возможных проблем с ранжированием сайта и повысите доверие поисковых систем.